RobustBench
A standardized benchmark for adversarial robustness
The goal of RobustBench is to systematically track
the real progress in adversarial robustness. There are
already
more than 3'000
papers
on this topic, but it is still unclear which approaches really work
and which only lead to
overestimated robustness. We start from benchmarking common
corruptions,
\(\ell_\infty\)- and
\(\ell_2\)-robustness since these are the most studied settings in the
literature. We use
AutoAttack, an
ensemble of white-box and black-box attacks, to standardize the
evaluation (for details see our paper) of the \(\ell_p\)
robustness and
CIFAR-10-C for the evaluation of robustness to common corruptions. Additionally,
we open source the
RobustBench library
that contains models used for the leaderboard to facilitate their
usage for downstream applications.
To prevent potential overadaptation of new defenses to AutoAttack, we also welcome external evaluations based
on adaptive attacks, especially where AutoAttack flags
a potential overestimation of robustness. For each model, we are interested in the best known robust accuracy
and see AutoAttack and adaptive attacks as complementary.
News:
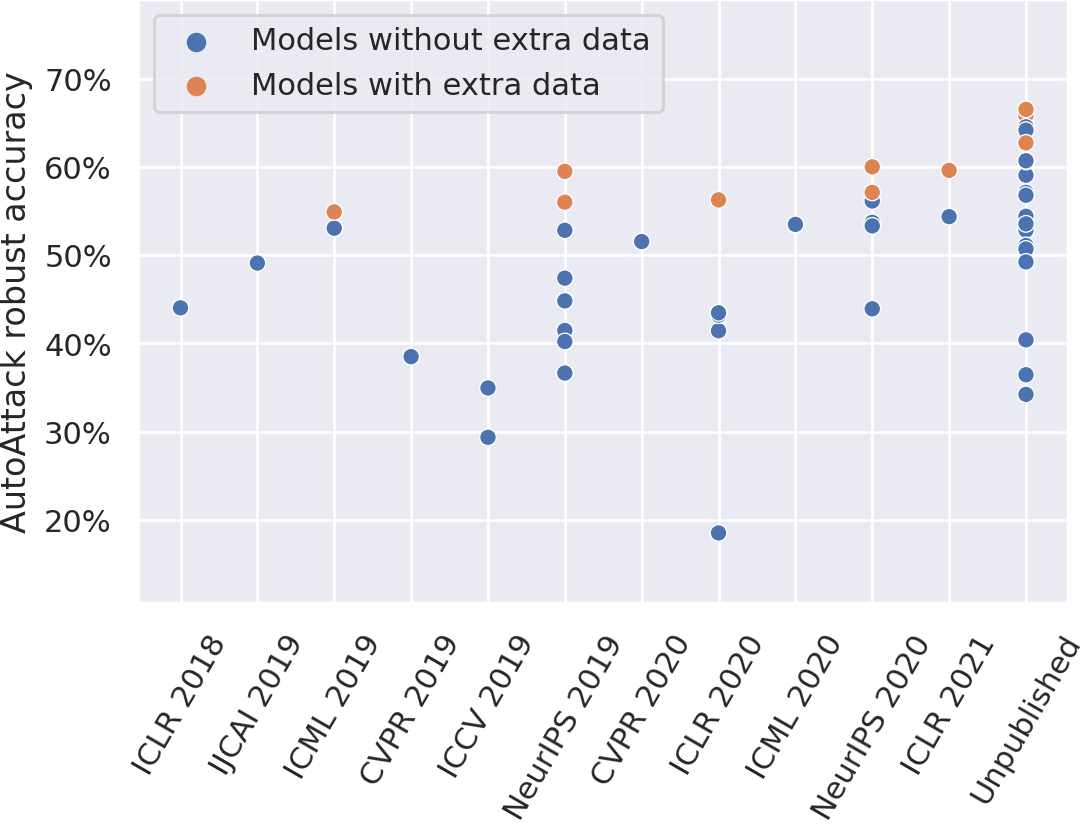
Up-to-date leaderboard based
on 120+ models

Unified access to 80+ state-of-the-art
robust models via
Model Zoo
Model Zoo
# !pip install git+https://github.com/RobustBench/robustbench@v0.2.1 from robustbench.utils import load_model # Load a model from the model zoo model = load_model(model_name='Rebuffi2021Fixing_70_16_cutmix_extra', dataset='cifar10', threat_model='Linf') # Evaluate the Linf robustness of the model using AutoAttack from robustbench.eval import benchmark clean_acc, robust_acc = benchmark(model, dataset='cifar10', threat_model='Linf')
Leaderboard: CIFAR-10, \( \ell_\infty = 8/255 \), untargeted attack
FAQ
➤ How does the RobustBench leaderboard differ from the
AutoAttack leaderboard? 🤔
The AutoAttack leaderboard was
the starting point of RobustBench. Now only the RobustBench leaderboard is actively maintained.
➤ How does the RobustBench leaderboard differ from
robust-ml.org? 🤔
robust-ml.org focuses on
adaptive evaluations, but we provide a
standardized benchmark. Adaptive evaluations have been very useful (e.g., see
Tramer et al., 2020),
but they are also very time-consuming and cannot be standardized by definition. Instead, we argue
that one can estimate robustness accurately mostly without adaptive
attacks but for this one has to introduce some restrictions on the
considered models (see our paper for more details).
However, we do welcome adaptive evaluations and we are always interested in showing the best known
robust accuracy.
➤ How is it related to libraries like
foolbox /
cleverhans /
advertorch? 🤔
These libraries provide implementations of different
attacks. Besides the standardized benchmark,
RobustBench additionally provides a repository of the
most robust models. So you can start using the robust models in one
line of code (see the tutorial
here).
➤ Why is Lp-robustness still interesting? 🤔
There are numerous interesting applications of Lp-robustness that
span transfer learning (Salman et al. (2020),
Utrera et al. (2020)),
interpretability (Tsipras et al. (2018), Kaur et al. (2019),
Engstrom et al. (2019)), security (Tramèr et al. (2018),
Saadatpanah et al. (2019)), generalization (Xie et al. (2019), Zhu et al. (2019),
Bochkovskiy et al. (2020)), robustness to unseen perturbations
(Xie et al. (2019), Kang et al. (2019)),
stabilization of GAN training (Zhong et al. (2020)).
➤ What about verified adversarial robustness? 🤔
We mostly focus on defenses which improve
empirical robustness, given the lack of clarity regarding
which approaches really improve robustness and which only make some
particular attacks unsuccessful.
However, we do not restrict submissions of verifiably robust models (e.g., we have
Zhang et al. (2019) in our CIFAR-10 Linf leaderboard).
For methods targeting verified robustness, we encourage the readers to check out
Salman et al. (2019)
and Li et al. (2020).
➤ What if I have a better attack than the one used in this
benchmark? 🤔
We will be happy to add a better attack or any adaptive evaluation
that would complement our default standardized attacks!
Citation
@article{croce2020robustbench, title={RobustBench: a standardized adversarial robustness benchmark}, author={Croce, Francesco and Andriushchenko, Maksym and Sehwag, Vikash and Debenedetti, Edoardo and Flammarion, Nicolas and Chiang, Mung and Mittal, Prateek and Matthias Hein}, journal={arXiv preprint arXiv:2010.09670}, year={2020} }
Contribute to RobustBench!